AES-128 Hardware Accelerator in Vitis HLS
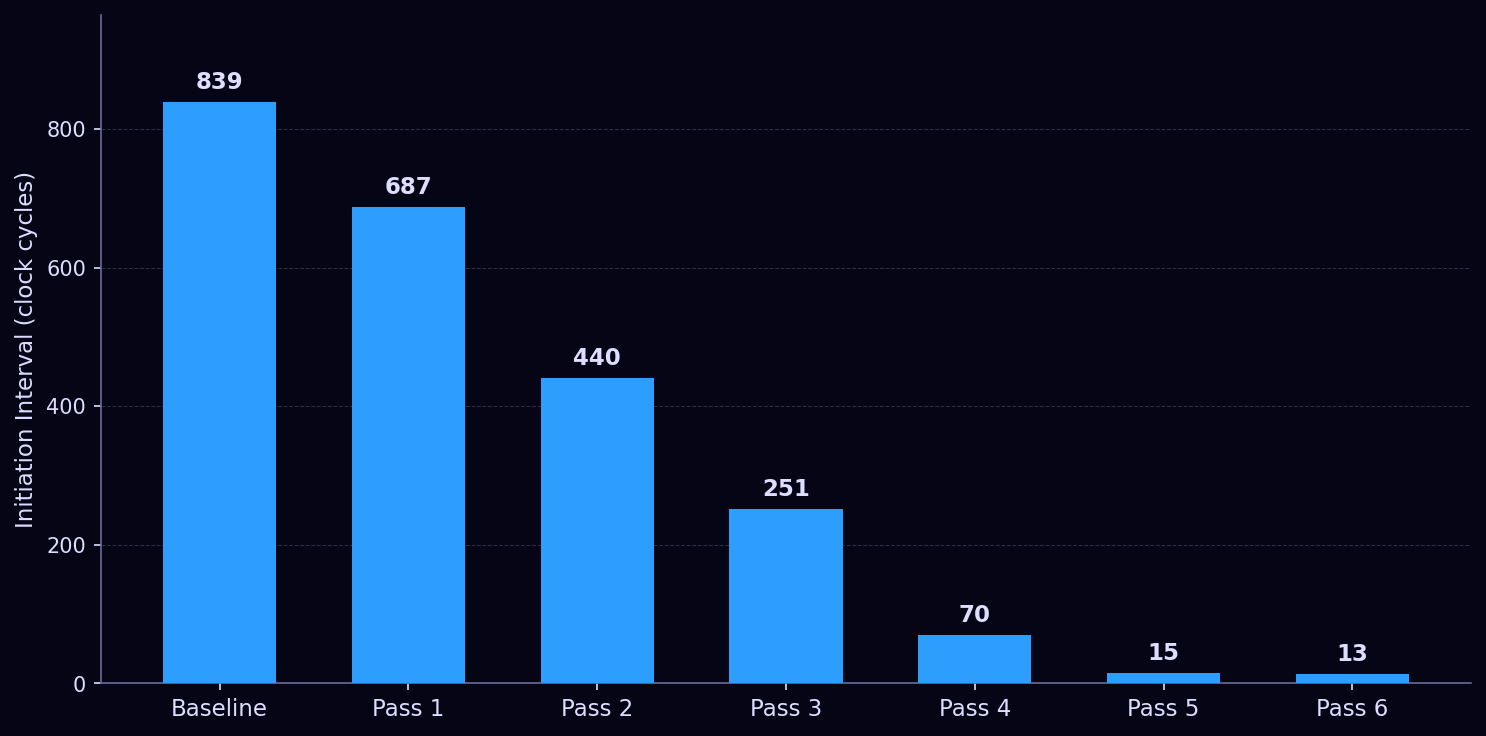
AES-128 implemented in C++ and compiled to hardware on a Xilinx Artix-7 FPGA — optimized across six passes from 839 clock cycles per block down to 13.
- Written in C++, synthesized to RTL via Vitis HLS
- Verified against FIPS 197 official test vectors
- Six optimization passes: array partitioning, loop unrolling, full inlining
- Initiation interval: 839 → 687 → 440 → 251 → 70 → 15 → 13
- Pipelined inner cipher: II=1, one new block accepted per clock cycle
Full writeup
What AES-128 Is
AES (Advanced Encryption Standard) is the dominant symmetric block cipher — it encrypts a fixed 128-bit block of plaintext using a 128-bit key, producing a 128-bit ciphertext. The algorithm operates on a 4×4 matrix of bytes called the state, running it through 10 rounds of four operations before producing output.
Each of the first 9 rounds applies, in order: SubBytes (a nonlinear substitution via a fixed 256-entry lookup table called the S-box), ShiftRows (a cyclic rotation of each row of the state matrix), MixColumns (a linear transformation of each column using multiplication in GF(2⁸)), and AddRoundKey (XOR with a round-specific subkey). The 10th and final round omits MixColumns. Before the first round, a zeroth AddRoundKey is applied. Decryption runs the inverse of each operation in reverse order.
All 11 subkeys — one per round plus the zeroth — are derived from the original key through a process called key expansion. The math throughout is in GF(2⁸), which means multiplication is implemented entirely with XOR and bit shifts rather than actual multiplication, making it highly amenable to hardware.
A cipher almost always lives inside a data pipeline, so the relevant performance metric is initiation interval — the number of clock cycles between accepting successive input blocks. Latency (cycles from input to output) matters for isolated single-block use, but II is what determines throughput. The Artix-7 is a small part that punishes logic-heavy designs, and the two goals — minimizing II for the inner pipeline and minimizing latency for the outer interface — turn out to pull in different directions, which becomes significant by the end of the optimization work.
The Baseline Implementation
The code is written in C++ using Xilinx's ap_int.h library, which provides arbitrary-precision integer types. The 128-bit key and plaintext are passed as ap_uint<128> values and unpacked into a 4×4 array of ap_uint<8> — the state matrix — before processing begins.
The S-box and its inverse are stored as 256-entry constant arrays in aes_consts.h. SubBytes is a pair of nested loops that replace each byte with its S-box entry. ShiftRows is written out manually as in-place swaps — no loop, just explicit index manipulation that mirrors the spec. MixColumns is a loop over four columns, each of which computes four new bytes via GF(2⁸) multiplication of the existing column values.
GF(2⁸) multiplication is implemented as a family of inline functions: xTimesTwo performs the fundamental GF doubling (a left shift XORed with the reduction polynomial 0x1b if the high bit was set), and the other multipliers (xTimesThree, xTimes09, xTimes0b, xTimes0d, xTimes0e) are built from chains of xTimesTwo calls. These exactly correspond to the coefficients in the MixColumns and InvMixColumns matrix.
Key expansion generates all 11 round keys into a [11][4][4] array of ap_uint<8>. It steps through words (columns) sequentially, applying RotWord, SubWord, and XOR with the round constant at the appropriate positions.
The top-level cipher function takes ap_uint<128> key and input, unpacks both, runs key expansion, applies all 10 rounds, and packs the result back into a ap_uint<128> output. Both encryption and decryption are verified against the test vectors from FIPS 197 Appendix B. The baseline synthesized with an initiation interval of 839.
Why Naive C++ Is Not Hardware-Efficient
High-Level Synthesis translates C++ into RTL — register-transfer level descriptions that map directly to gates and flip-flops. The translation is mechanical, and it preserves the sequential structure of the source unless explicitly directed otherwise. A loop that runs 10 times becomes 10 sequential operations in hardware; an array becomes a block RAM with limited ports. The baseline implementation has several structural properties that make it hardware-inefficient by default.
The round loop serializes all 10 rounds. The loop for (int i = 1; i < 10; i++) aesRound(...) produces a design that completes round one, then starts round two, then round three, and so on. Latency is approximately 10× the latency of a single round. HLS has no reason to assume otherwise — it takes the sequential semantics of C++ literally.
Array accesses create memory bottlenecks. The state and round key arrays map to block RAM (BRAM) by default. BRAM supports at most two ports. In subBytes, the loop reads and writes all 16 state bytes — but with a two-port BRAM, only two accesses can occur per clock cycle, serializing the rest. The same problem appears in mixColumns, addRoundKey, and the key expansion loop. Even if the round loop were parallelized, memory access patterns would remain a bottleneck.
Key expansion happens every call. Every invocation of cipher recomputes all 11 round keys from scratch. This is 40 iterations of the key schedule loop, each with conditional logic, memory reads, and writes. In scenarios where the key is static or changes infrequently, this is dead work on every block encrypted.
No interface protocol is specified. The top-level function's port protocol is left to HLS defaults. For integration into a larger system — an AXI-based SoC, a streaming pipeline — the interface must be explicit. An unspecified interface may synthesize correctly in isolation but fail to integrate.
Optimization
First Pass
The first pass applied array partitioning, pipelining, and a structural rewrite of key expansion.
Array partitioning was applied to every array in the critical path. The state matrix was partitioned complete across both dimensions, giving HLS 16 independent registers instead of a two-port BRAM. The roundKeys[11][4][4] array was partitioned complete across all three dimensions — all 176 bytes become individual registers, accessible simultaneously. The local column[4] array inside mixColumns received the same treatment, resolving the II violation that had prevented pipelining that function.
Pipeline and loop_flatten pragmas were added to mixColumns and the key expansion loops. loop_flatten collapses nested loops into a single loop level where possible, which gives the scheduler a larger window to find parallelism and simplifies the initiation interval analysis.
Key expansion was rewritten as keyExpansionOptimized, splitting the original single loop into two specialized functions. The original loop had a branch: column 0 of each round requires RotWord, SubWord, and RCon mixing, while columns 1–3 are just XOR with the previous column. That conditional structure made pipelining difficult.
firstColExpand handles column 0 by inlining all three operations directly into four independent assignment statements. The rotation is absorbed into the source indices — rather than rotating a temporary array and then S-boxing it, the rotated position is computed directly as the index into the previous round's last column. The tempWord intermediate array is eliminated entirely. All four assignments are now data-independent and can execute in parallel. midColExpand handles columns 1–3 as a straightforward XOR loop.
cipher was refactored to delegate to cipherArrays rather than reimplementing the round logic inline. The outer function now only handles packing and unpacking the ap_uint<128> interface values; the actual cipher logic lives in one place.
This pass brought II from 839 to 687.
Second Pass
The second pass focused on giving the HLS scheduler broader visibility into the design and removing hazards that prevented parallelism inside the round operations.
Double loops were flattened to single linear loops in subBytes and addRoundKey. Instead of nested i, j loops over [4][4], both functions were rewritten as a single k = 0..15 loop using k/4 and k%4 for indexing, with #pragma HLS UNROLL. A flat loop with a compile-time-constant bound is easier for the scheduler to fully unroll into 16 parallel operations.
subBytes got a local S-box copy. Rather than reading from the global SBox array, the function declares its own local copy. This lets HLS infer a function-scoped ROM with access patterns it can reason about independently, rather than sharing the global with other functions that also read it.
mixColumns was restructured to eliminate a read-write hazard. The original implementation read from state while also writing back to it in the same loop, which forced sequential execution. The fix was to snapshot the entire state into a separate columns[4][4] array (fully partitioned across both dimensions) before the loop, then read exclusively from columns while writing to state. With no overlap between reads and writes, all four columns can be computed simultaneously.
aesRound and finalRound got #pragma HLS INLINE on each sub-function call. This forces subBytes, shiftRows, mixColumns, and addRoundKey to be inlined into the calling function rather than instantiated as separate modules. With everything inlined, the scheduler sees the full round as a single flat block of logic and can schedule across function boundaries.
The round loop in cipherArrays was unrolled with #pragma HLS UNROLL. Combined with the inlining above, all 10 rounds are now visible to the scheduler as one continuous computation rather than 10 sequential calls to a black-box function.
This pass brought II from 687 to 440.
Third Pass
The columns[4][4] snapshot introduced in the previous pass turned out to be unnecessary overhead. The read-write hazard it was solving can be handled more simply: read each column's four values into four scalar locals at the top of the loop iteration, then compute all four output bytes from those scalars. Scalars don't map to RAM — they become registers — so there's no port contention and no need for a separate partitioned array. The memcpy and the intermediate array are gone, replaced by four local variable reads per iteration. II dropped from 440 to 251.
Fourth Pass
The remaining pipeline pragmas on loops where full parallelism was achievable were switched to unroll. The most impactful was mixColumns: previously the four-column loop was pipelined, processing one column per pipeline stage. Unrolling it instead computes all four columns simultaneously — the scalar locals from the previous pass make this safe, since each iteration reads from the original values and writes to independent output positions. bytesToArray128 received the same treatment, its nested loop collapsed to a flat 16-iteration unrolled loop. Pipeline pragmas were also added around the memcpy calls at the entry and exit of cipherArrays to ensure the pack and unpack steps don't become bottlenecks at the boundary. II dropped from 251 to 70.
Fifth Pass
Two changes in this pass. First, a bug fix: the output packing loop in cipher had k < 4 instead of k < 16, meaning only the first row of the output array was being packed into the result. The corrected loop produces valid 128-bit ciphertext.
Second, aggressive inlining throughout. #pragma HLS INLINE was added to every sub-function — subBytes, shiftRows, mixColumns, addRoundKey, firstColExpand, midColExpand, and keyExpansionOptimized. With everything inlined into cipherArrays, the scheduler sees the entire cipher — all 10 rounds plus key expansion — as a single flat block of logic, with no function call boundaries limiting its scheduling decisions.
The local S-box copy introduced in the second pass was dropped in favor of partitioning the global SBox array directly with #pragma HLS ARRAY_PARTITION variable=SBox dim=1 complete. This gives all 256 entries as independent registers, allowing all 16 SubBytes lookups across a fully unrolled round to read simultaneously. Even so, each lookup still requires a 256:1 multiplexer — 8-bit addressing of 256 independent signals requires multiple levels of 2:1 muxes regardless of partitioning. On a small Artix-7, routing 16 of these muxes simultaneously means routing delay dominates over logic depth, and SubBytes still consumes approximately one full clock period. This is a floor imposed by the ROM lookup approach on a constrained device, not a code quality issue.
Both loops in keyExpansionOptimized were also fully unrolled, expanding all 10 rounds of key schedule generation into parallel logic.
An instructive observation emerged during this pass: cipherArrays reported II=1 while cipher reported a much higher II. These measure different things. cipherArrays is fully pipelined — it can accept a new plaintext block every clock cycle, with 69 cycles of latency before the result emerges. cipher wraps it and adds array conversion at the boundaries, which is not pipelined, so its II reflects the full latency of one complete encryption. For throughput-oriented use cases, cipherArrays is the right entry point; cipher is a convenience wrapper for single-block use.
II dropped from 70 to 15.
Sixth Pass
#pragma HLS INLINE was moved from call sites into the function definitions themselves for subBytes, shiftRows, mixColumns, and keyExpansionOptimized. A call-site pragma only inlines at that specific call; a definition-level pragma makes every call to that function inline unconditionally. The distinction matters once the design is large enough that the scheduler might otherwise treat a function as a black-box module. Call-site pragmas had been used throughout earlier passes under the assumption they were equivalent — discovering they weren't, and that some functions were being treated as black boxes as a result, was a significant debugging step. II dropped from 15 to 13.
Conclusion
The optimization journey from II=839 to II=13 is largely a story of removing artificial bottlenecks — BRAM port contention, unnecessary intermediate arrays, opaque function boundaries, sequential loops over statically-bounded data — until what remained was the structure of the algorithm itself.
AES has an irreducible sequential dependency chain. Round i+1's state cannot begin computing until round i is complete, because the output of one round is the input to the next. The same holds for key expansion: round key i+1 depends on round key i, so the 10-round key schedule is a sequential chain regardless of how aggressively the surrounding logic is unrolled. These are hard data dependencies — no pragma can remove them.
With 10 rounds of cipher and 10 rounds of key expansion each forming such a chain, the theoretical floor for a single-block sequential AES implementation is approximately 10 clock cycles: one per round, assuming each round's combinatorial logic fits within a single clock period. At II=13, the gap above that floor is small — likely the zeroth AddRoundKey, the modified final round, and some pipeline overhead at the pack and unpack boundary.
The alternative is a parallel architecture: accept a new plaintext block every cycle, process multiple blocks simultaneously in different pipeline stages, and achieve II=1 at the cost of replicating the full round logic across every stage. That trades area for throughput in a fundamentally different way. For a single-block sequential implementation on a constrained device like the Artix-7, II=13 represents a near-optimal result — not because the implementation is perfect, but because it has run out of algorithmic slack to exploit.